On-disk HNSW index for Postgres with pg_embedding
Learn about pg_embedding's latest updates

A few weeks back, we released pg_embedding, a new extension for Postgres and LangChain which introduced Hierarchical Navigable Small Worlds (HNSW) indexes for vector similarity search. This new indexing method resulted in 20x faster queries at a 99% accuracy compared to traditional IVFFlat indexing.
Today, we’re thrilled to announce the newest version of pg_embedding, which includes the following improvements:
- The HNSW index is now constructed on disk instead of in memory.
- The extension now supports cosine similarity, Manhattan distance, and Euclidean distance (also known as L2).
With this new release, you can take full advantage of Neon features which allow your AI and LLM apps to scale to millions of users, including:
- Autoscaling to meet your application demands
- Scaling to zero to reduce costs related to your compute nodes
- Read replicas for read-heavy workloads
Getting started with pg_embedding
In case you’re unfamiliar, pg_embedding makes it possible to store vector embeddings in Postgres and provides functions to calculate the similarity between vectors. This is incredibly useful because it eliminates the need to introduce an external vector store when building AI and LLM applications. To get started:
- Enable the extension
CREATE EXTENSION embedding
2. Create a column for storing vector data
CREATE TABLE documents(id integer PRIMARY KEY, embedding real[]);
INSERT INTO documents(id, embedding) VALUES (1, '{1.1, 2.2, 3.3}'),(2, '{4.4, 5.5, 6.6}');
3. Run similarity search queries
SELECT id FROM documents ORDER BY embedding <=> ARRAY[1.1, 2.2, 3.3] LIMIT 1;
This query retrieves the ID from the documents table, sorts the results by the shortest distance between the embedding column and the array [1.1, 2.2, 3.3], and returns only the first result.
Speeding up your queries using HNSW indexing
As the number of embeddings you’re storing grows, running the above query can take a significant amount of time. That’s because the query performs a full table scan and compares the cosine similarity for each row, which is time-consuming and resource-intensive.
To avoid doing a full table scan, you can create an index on the embedding column. This would enable the database to quickly locate and retrieve the necessary data for sorting, resulting in faster query execution.
You can run the following query to create an HNSW index on the embedding column:
CREATE INDEX ON documents USING hnsw(embedding ann_cos_ops) WITH (dims=3, m=8, efconstruction=8, efsearch=8);The following options allow you to tune the HNSW algorithm when creating an index:
dims: Defines the number of dimensions in your vector data. This is a required parameter.m: Defines the maximum number of links or “edges” created for each node during graph construction. A higher value increases accuracy (recall) but also increases the size of the index in memory and index construction time.efConstruction: Influences the trade-off between index quality and construction speed. A highefConstructionvalue creates a higher quality graph, enabling more accurate search results, but a higher value also means that index construction takes longer.efSearch: Influences the trade-off between query accuracy (recall) and speed. A higherefSearchvalue increases accuracy at the cost of speed. This value should be equal to or larger than k, which is the number of nearest neighbors you want your search to return (defined by theLIMITclause in yourSELECTquery).
After the index is built (which can take some time, depending on the size of your data), you should experience significantly faster queries.
HNSW Index on-disk vs. in-memory
We tested pg_embedding’s HNSW index in-memory and on-disk implementations on an 8vCPU and 32 GB of RAM, and unsurprisingly, the in-memory index is typically 2x faster than the on-disk one.
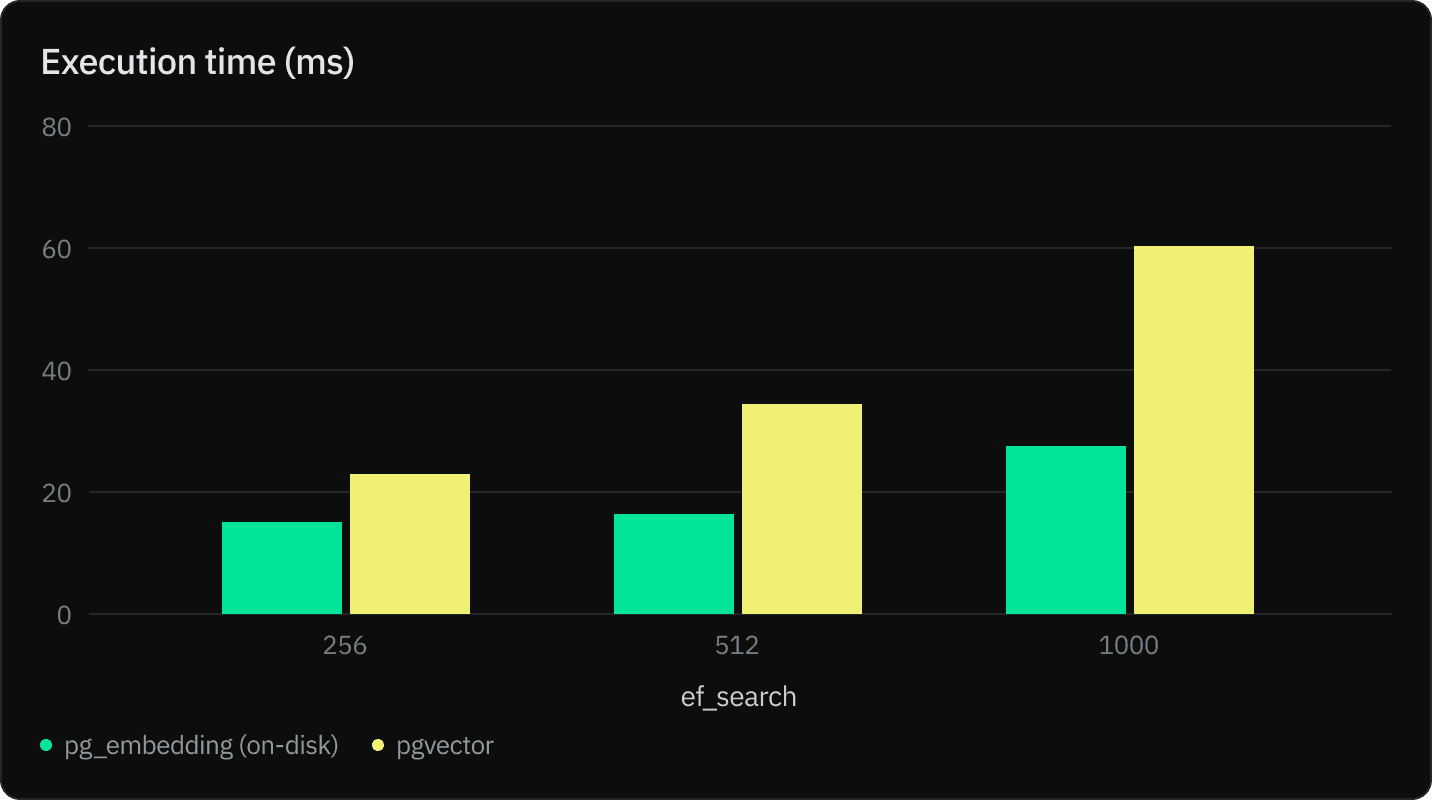
So why do we sacrifice performance by persisting the index? The short answer is to scale your AI applications and take full advantage of Neon’s serverless architecture.
Scalable vector search on Neon
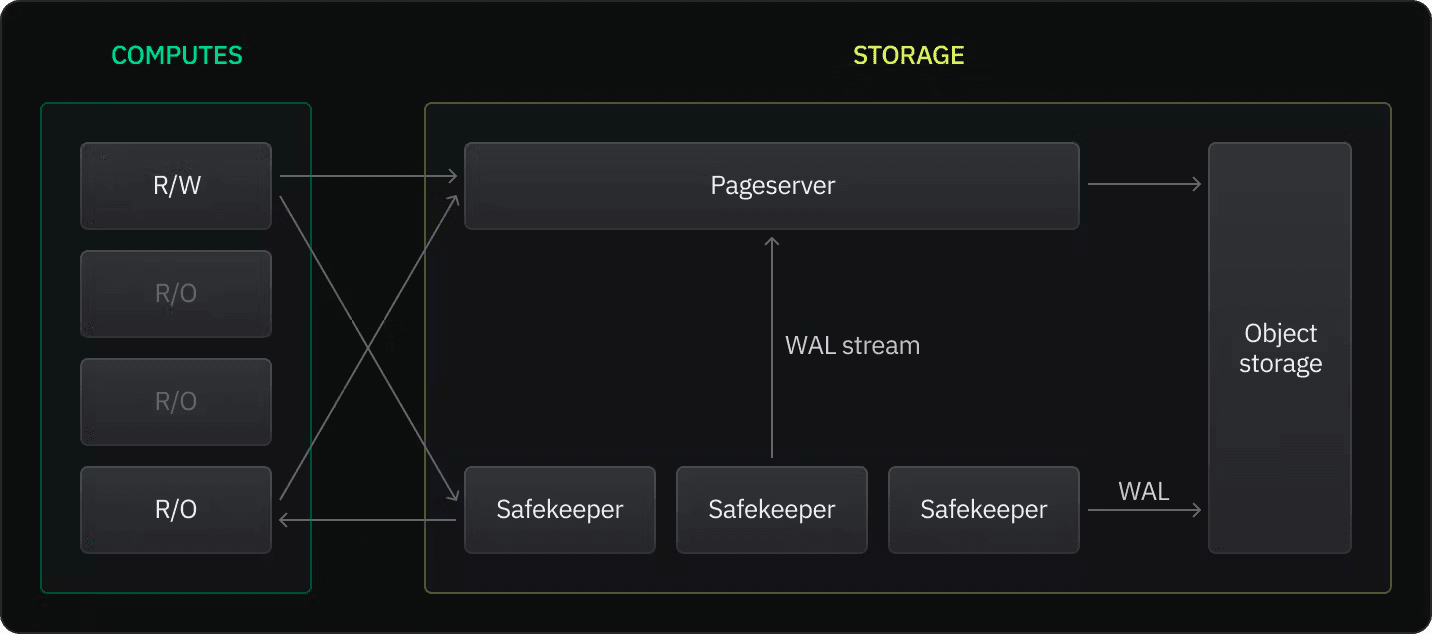
Neon is a fully managed serverless Postgres. This means you do not have to pick a size for your database upfront, and it will automatically allocate resources to meet your database’s workload. This is possible because Neon’s architecture separates storage and compute.
This architecture allows Neon to automatically scale up compute on demand in response to application workload and down to zero on inactivity. Since Neon is serverless, you’re only charged for what you use.
Furthermore, Neon supports regional read replicas, which are independent read-only compute instances designed to perform read operations on the same data as your read-write computes. Read replicas do not replicate data across database instances since storage and compute are separate. Instead, read requests are directed to a single source.
Since vector similarity search is a read-heavy workload, you can leverage read replicas to offload reads from your read-write compute instance to a dedicated read-only compute instance when building AI and LLM applications.
Finally, you can experience reduced query latencies by using the Neon serverless driver, which makes it possible to achieve sub-10ms Postgres queries when querying from Edge functions.
Combining these features enables you to build scalable AI/LLM applications.
Final thoughts
If you’re already using pg_embedding for your project, first of all, thank you! We appreciate you being an early adopter of the extension. If you would like to use the newest version of the extension, check out the upgrade guide in our docs.
We’re excited about this new release of pg_embedding, and we plan on ensuring Neon users have a great experience when building their AI/LLM applications. Feel free to reach out on Twitter or our community forum if you have any questions or feedback, we’d love to hear from you.
Also, if you are new to Neon, you can sign up today for free.